CPO伺服器與矽光子:AI 從算力競賽,走向互連架構革命
- 2月3日
- 讀畢需時 9 分鐘
已更新:3月26日
此篇文章重點涵蓋: 1. 銅線的物理極限、邁入光速傳輸的必然趨勢 2. CPO 用於晶片與伺服器,讓傳輸更貼近計算核心 3. CPO 產業的結構問題,與技術轉折點 4. CPO 倚賴整體傳輸架構協作、與封裝前量測測試
在全球資料中心的算力軍備競賽中,頂尖 GPU 的運算能力雖已足以應付海量 AI 工作負載,但 AI 系統的整體效能早已不再只取決於運算核心本身,而是受限於「資料如何被搬運」。從 CPU 與 GPU、ASIC 之間的晶片對晶片傳輸,到機架與機架之間的高速互連,頻寬、延遲與功耗正成為擴展 AI 規模的關鍵瓶頸。
也正是在這樣的背景下,CPO 伺服器(Co-Packaged Optics Server)被視為突破傳統銅纜與可插拔光模組限制的重要方向。
從目前產業時程觀察,Scale-out CPO 的大規模導入仍面臨現實挑戰。即便 Nvidia 規劃於 2027 年推出 Rubin Ultra 平台,供應鏈短期內仍難以支撐數以千萬計的 CPO 端點需求,因此真正的 CPO 注入拐點,業界普遍認為將落在後續,預期 2028 年的 Feynman 世代,成為 CPO 伺服器正式進入 AI 生態系的關鍵起點。
黃仁勳曾指出:傳統銅纜無法應對 AI 伺服器內部功耗過高、訊號損耗嚴重的窘境;各大科技巨頭已加速佈局 CPO 方案。目前業界針對 Feynman 前景、CPO Switch(共同封裝光學交換機) 技術已有廣泛討論,科技巨頭的下一步,是「將 CPO 技術直接導入 GPU 伺服器」,建立更直接的光互連 AI 運算平台。


CPO伺服器的進化從何而來?AI 傳輸到底有多快?
幾年前,網路傳輸的瞬間資料吞吐量在 100~400G 以內時,「晶片間 Chip-to-Chip」與「機櫃內部 Intra Rack」計算節點與連接介面主要依賴銅纜 / 電訊號傳輸。而 CPO 技術則用於大型資料中心的機櫃間 Rack-to-Rack 傳輸(距離約 5M 以上)與長程光纖(跨地區,距離數公里以上)。
AI 時代的資料傳輸速度,訓練叢集翻倍至 800G、1.6T 甚至未來 3.2T;這樣的速度意味著,每秒需同步傳輸數十部 4K 電影的資料量,且必須在晶片、伺服器與機架之間持續雙向流動。且 AI 資料中心的晶片、機櫃規模也倍數擴增(GPU 叢集從數千顆擴展至數十萬顆等級),與 GPU、DPU、Switch 做即時資料交換(搬運模型、權重、梯度、token 等)。晶片間 I/O 頻寬需求呈現非線性成長,CPU 的瓶頸不在運算,而在 I/O,而 I/O 功耗開始比核心功耗更大,受限於高速傳輸的物理限制。

銅線的物理極限、與邁入光速傳輸的必然趨勢
速度越快,銅纜能跑的距離就越短。傳輸頻率不斷升高,銅線傳輸物理效能已達極限:頻率越高訊號衰減越劇烈,產生大量熱耗與功耗牆(Power Limit),加上集膚效應(電子偏向導體表面流動),使無源銅纜傳輸距離被壓縮到僅剩幾公分的範圍。因此在前段的情境下,AI 系統不可能再使用銅纜,傳統光模組與可插拔光學元件雖然能延伸一部分傳輸距離,無法根本改善功耗與密度瓶頸。
而矽光子(Silicon Photonics)與 Co-Packaged Optics(CPO) 技術,正是這場革命的核心解方。
光傳輸深入伺服器:矽光子、CPO、AI 伺服器互聯的技術基礎
一、矽光子(Silicon Photonics)— 光與電子融合的新介面

矽光子是一種使用矽基材料製作的積體光路(Photonic Integrated Circuit, PIC) 的技術,它能將光波導、雷射器、調製器與探測器等光學元件集成在矽晶片上,透過成熟的 CMOS 製程達到高密度、低功耗的光訊號傳輸。矽光子的核心優勢包括:
光子的自由度極為豐富,可用來編碼與傳遞資訊的變化度極高
傳輸的速度、吞吐量遠優於電子。
矽光子將光訊號直接在晶片內傳輸,降低訊號 I/O 損耗與延遲
可利用現有半導體製程技術改良,提升良率與量產能力
面對前文所述的 800G、1.6T 吞吐量危機,銅纜「跑不動」的距離越來越短,取而代之的光傳輸從長距離光纖,一步步深入至伺服器、GPU 內的晶片溝通。
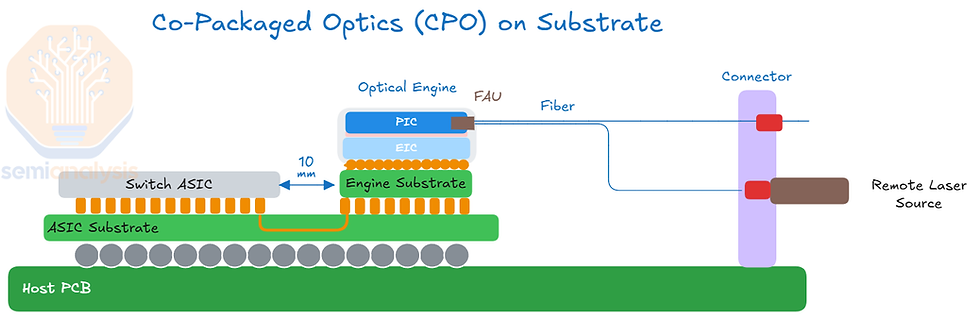
二、共同封裝光學(CPO)— 光學引擎更貼近計算核心
CPO 是一種先進封裝技術,其目標是將光學引擎與電子晶片(如 GPU、ASIC 或交換晶片)共同封裝至同一底板或一體化封裝內。它的關鍵目標為:
大幅縮短電子路徑距離,使電訊號能在最短距離內轉換為光訊號,大幅改善訊號完整性
省去了傳統電路中複雜的中繼訊號補償、驅動電路,大幅降低功耗與延遲
傳統面板空間難以支撐更多數量的可插拔埠位,而 CPO 能將系統總頻寬提升至 >75T 以上
提高頻寬密度,支援 1.6T、3.2T 甚至更高級別的資料傳輸
突破功耗牆:傳統可插拔模組的光電轉換過程消耗大量電力。CPO 則能顯著降低能耗,達到 <3pJ/bit 的極低功耗
這種封裝方式幾乎拋棄了傳統可插拔光模組的設計,讓光直接靠近計算核心,光在晶片內要走的距離更短,提高訊號完整性與系統能效。

三、CPO 的 MRM 技術創新 — 實現交換機內光纖直接互連、尺寸縮小千倍
在矽光子技術的關鍵創新上,微型環調製器(Micro-Ring Modulator, MRM) 成為提升頻寬密度與能效的核心元件。MRM 透過微小的環狀光學諧振結構,對特定波長的雷射光進行高效率調製,可將光學元件尺寸縮小數個量級,並結合多波長雷射(WDM)大幅提升單位面積的傳輸能力。
在 NVIDIA 於 GTC 公布的最新進展中,其首款矽光子交換器即採用 MRM 技術,並整合於台積電製程,實現交換器內部直接光纖互連、無需傳統收發器的 CPO 架構(這就讓矽光子晶片的組件尺寸能縮小千倍),支援高達 512 埠的超高密度連接,同時顯著降低功耗與系統成本。此類矽光子 CPO 架構被視為支撐未來數十萬甚至數百萬 GPU 規模 AI 叢集的關鍵基礎,並在機架層級展現出大幅節能的潛力。

CPO 為何現在才落地?從產業結構問題到技術轉折點
儘管 CPO 理論上能顯著降低功耗、延遲並提升頻寬密度,但過去二十年始終未能大規模商用,限於可維護性與系統可靠度的現實挑戰。與可插拔光模組採用預對準、標準化光纖連接器不同,CPO 必須將光纖直接耦合至封裝內的光引擎,對準精度需達亞微米等級,製程與組裝難度大幅提高。
CPO製程的光敏感性、穩定性挑戰
在工程層面,CPO 導入 GPU 與交換器平台時,必須同時面對高密度通道測試、光纖路由與耦合精度、嚴苛的熱管理,以及 PIC/EIC 異質整合帶來的良率與可靠性挑戰;在產業層面,封裝與製造流程高度複雜,使整體成本顯著高於可插拔光模組,且缺乏成熟的跨供應鏈標準與互通性。
此外,CPO 的光纖必須以亞微米級的精度精確對準,才能將光耦合到晶片上極小的波導(通常寬度和高度都小於1微米);耦合發生在空間高度受限、溫度顯著偏高的 GPU 或交換器機箱內,進一步放大熱漂移、機械應力與裝配誤差對系統穩定性的影響。光子元件本身對溫度變化高度敏感,雷射波長漂移不僅會降低傳輸效率,也會影響長期可靠性,往往需要額外的溫控或動態校準機制。
在 CPO 實際部署環境中,灰塵、濕度與微小機械擾動都可能導致光學效率隨時間衰退,而光纖對彎折極為敏感,不當佈線會同時增加插入損耗與故障風險。當單一系統內包含多組光纖陣列時,每條光纖的長度、路由與彎曲半徑都必須精密設計,否則將顯著降低整體系統可維護性。
因此過往 800G 以下的傳輸速率時,資料中心廠商比起高風險、製成不易又高成本的 CPO 技術,更傾向長期依賴 OSFP、QSFP-DD 等已經成熟、標準化的可插拔收發器方案。可插拔光模組技術今天仍然持續發展,在多數應用情境下仍能滿足效能/成本/風險綜合需求,進一步延後了 CPO 的技術演化。
CPO伺服器 - 仰賴架構協作、階段測試與量測
一、CPO技術不看單一晶片效能,而是整體傳輸架構協作
現今的 CPO 製成目標,不再僅是「把光學搬進封裝」,而是追求一套同時解決頻寬擴展、能效瓶頸、可靠度與可維護性的「整體架構設計」。CPO 透過將光引擎與 GPU 或交換 ASIC 共封裝,CPO 能大幅縮短電氣互連距離,移除可插拔模組中的 DSP,改採低功耗短距離 SerDes 或寬 I/O 架構,從根本降低功耗與熱源集中問題。
在光學層面,高密度光纖陣列、精密封裝與波導耦合技術,搭配 WDM 架構,可在有限光纖數量下持續擴展總頻寬;在機構與熱設計層面,針對光子元件的溫度敏感性,導入更精細的散熱分區、溫控與即時校準機制,逐步改善長期穩定性;而在量產關鍵上,測試平台與自動化校準能力的成熟,正降低亞微米級對準與高通道數驗證的門檻。
二、CPO伺服器倚賴封裝前量測測試,把關光引擎
在傳統可插拔光模組架構中,光模組故障可透過更換單一模組快速排除;然而 CPO 架構光引擎與交換 ASIC 或 GPU 直接共封裝,一旦發生效能異常,影響的不再是單一鏈路,而可能牽動整顆晶片、整張板卡,甚至整個機架的運作穩定性。
加上 CPO 系統內部動輒包含數百到上千條光通道,任何微小的光損耗、偏移/老化、雷射波長漂移、光學元件老化、光纖彎曲造成的插入損耗,甚至微小的污染與機械擾動,都可能導致 BER 上升或鏈路不穩定,被放大為系統級風險,使「可預測、可驗證的量測能力」成為關鍵基礎。
CPO 邁向量產,高度依賴從晶片、光引擎、光纖到系統層級的「全流程測試與量測」能力,包括高密度通道的光功率、BER、抖動、時序、光譜與溫度行為分析,以及在實際機箱環境中的鏈路驗證。在量產前、部署中與長期運行階段,皆須建立完整的測試與監控機制。
目前已有眾多國際性光通訊測試大廠,如《VIAVI Solutions》等,投入於光通訊與高速互連測試的技術,透過可擴展、可重複的量測平台,協助設備商與資料中心在 CPO 架構下,將不可更換的光引擎,轉化為「可被精準驗證與長期監控的系統元件」。



CPO伺服器 + 矽光子技術 — AI 運算互聯的未來基石
雖然 CPO 在製程成熟度、可維護性與標準化上仍面臨挑戰,但在銅線已逼近物理極限的前提下,CPO 幾乎是唯一能持續推進頻寬密度、能效與系統可擴展性的可行路徑。
隨著 AI 模型規模與叢集節點數量呈指數型成長,運算效能的決定因素正從「單顆晶片性能」轉向「整體互連架構效率」。在此趨勢下,CPO 結合矽光子 PIC,不僅能在極高 I/O 密度下實現低延遲、低功耗的光互連,更為數十萬乃至百萬 GPU 等級的資料中心提供可持續擴展的基礎。
未來 AI 基礎設施的競爭,將不再只是算力之爭,而是以 CPO 與矽光子主導,兼具光電整合能力、系統架構設計,以及測試與驗證體系成熟度的綜合較量。《Eagletek 翔宇科技》代理《VIAVI Solutions》、《Bird RF》、《Rohde Schwarz》等國際性量測大廠解決方案至臺灣,幫助客戶突破研發瓶頸、有效降低研發複雜度、提升產品良率並縮短上市時間。歡迎隨時聯繫翔宇技術團隊,讓我們一起突破算力瓶頸。




